Logika fuzzy pertama kali dikembangkan oleh Lotfi A. Zadeh, seorang ilmuan Amerika Serikat berkebangsaan Iran dari universitas California di Barkeley, melalui tulisannya pada tahun 1965.( Munir, R. 2005).[5]
Fuzzy secara bahasa diartikan sebagai kabur atau samar-samar. Suatu nilai dapat bernilai benar atau salah secara bersamaan. Dalam fuzzy dikenal derajat keanggotaan yang memiliki rentang nilai 0 (nol) hingga 1(satu). Berbeda dengan himpunan tegas yang memiliki nilai 1 atau 0 (ya atau tidak).
Logika fuzzy adalah suatu cara yang tepat untuk memetakan suatu ruang input kedalam suatu ruang output, mempunyai nilai kontinyu. Fuzzy dinyatakan dalam derajat dari suatu keanggotaan dan derajat dari kebenaran. Oleh sebab itu sesuatu dapat dikatakan sebagian benar dan sebagian salah pada waktu yang sama (Kusumadewi. 2003). [4]
Clustering
Clustering adalah suatu metode pengelompokan berdasarkan ukuran kedekatan(kemiripan).Clustering beda dengan group, kalau group berarti kelompok yang sama,kondisinya kalau tidak ya pasti bukan kelompoknya.Tetapi kalau cluster tidak harus sama akan tetapi pengelompokannya berdasarkan pada kedekatan dari suatu karakteristik sample yang ada
Macam-macam metode clustering :
- Berbasis Metode Statistikk
- Hirarchical clustering method : pada kasus untuk jumlah kelompok belum ditentukan terlebih dulu, contoh data-data hasil survey kuisioner. Macam-metode jenis ini: Single Lingkage,Complete Linkage,Average Linkage dll.
- Non Hirarchical clustering method: Jumlah kelompok telah ditentukan terlebih dulu.Metode yang digunakan : K-Means.
- Berbasis Fuzzy : Fuzzy C-Means
- Berbasis Neural Network : Kohonen SOM, LVQ
- Metode lain untuk optimasi centroid atau lebar cluster : Genetik Algoritma (GA)
Fuzzy C-Means
Fuzzy clustering adalah proses menentukan derajat keanggotaan, dan kemudian menggunakannya dengan memasukkannya kedalam elemen data kedalam satu kelompok cluster atau lebih.
Hal ini akan memberikan informasi kesamaan dari setiap objek. Satu dari sekian banyaknya algoritma fuzzy clustering yang digunakan adalah algoritma fuzzy clustering c means. Vektor dari fuzzy clustering, V={v1, v2, v3,…, vc}, merupakan sebuah fungsi objektif yang di defenisikan dengan derajat keanggotaan dari data Xj dan pusat cluster Vj.
Algoritma fuzzy clustering c means membagi data yang tersedia dari setiap elemen data berhingga lalu memasukkannya kedalam bagian dari koleksi cluster yang dipengaruhi oleh beberapa kriteria yang diberikan. Berikan satu kumpulan data berhingga. X= {x1,…, xn } dan pusat data.
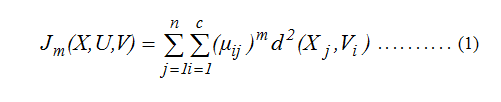
Dimana μ ij adalah derajat keanggotaan dari Xj dan pusat cluster adalah sebuah bagian dari keanggotaan matriks [μ ij]. d2 adalahakar dari Euclidean distance dan m adalah parameter fuzzy yang rata-rata derajat kekaburan dari setiap data derajat keanggotaan tidak lebih besar dari 1,0 Ravichandran (2009).[9]
Output dari Fuzzy C-Means merupakan deretan pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data. Informasi ini dapat digunakan untuk membangun suatu fuzzy inference system.
Algoritma Fuzzy Clustering Means (FCM)
Algoritma Fuzzy C-Means adalah sebagai berikut:
- Input data yang akan dicluster X, berupa matriks berukuran n x m (n=jumlah sample data, m=atribut setiap data). Xij=data sample ke-i (i=1,2,…,n), atribut ke-j (j=1,2,…,m).
- Tentukan :
- Jumlah cluster = c
- Pangkat = w
- Maksimum iterasi = MaxIter
- Error terkecil yang diharapkan = ξ
- Fungsi obyektif awal = Po =0
- Iterasi awal = t =
- Bangkitkan nilai acak μik, i=1,2,…,n; k=1,2,…,c sebagai elemen-elemen matriks partisi awal μik. μik adalah derajat keanggotaan yang merujuk pada seberapa besar kemungkinan suatu data bisa menjadi anggota ke dalam suatu cluster.Posisi dan nilai matriks dibangun secara random. Dimana nilai keangotaan terletak pada interval 0 sampai dengan 1. Pada posisi awal matriks partisi U masih belum akurat begitu juga pusat clusternya. Sehingga kecendrungan data untuk masuk suatu cluster juga belum akurat.

- Hitung pusat Cluster ke-k: Vkj ,dengan k=1,2,…c dan j=1,2,…m. dimana Xijadalah variabel fuzzy yang digunakan dan w adalah bobot.
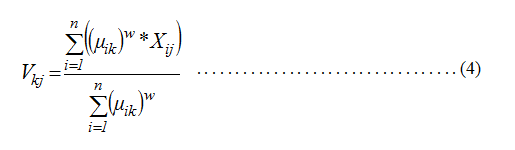 Fungsi objektif digunakan sebagai syarat perulangan untuk mendapatkan pusat cluster yang tepat. Sehingga diperoleh kecendrungan data untuk masuk ke cluster mana pada step akhir.
Fungsi objektif digunakan sebagai syarat perulangan untuk mendapatkan pusat cluster yang tepat. Sehingga diperoleh kecendrungan data untuk masuk ke cluster mana pada step akhir.
- Hitung fungsi obyektif pada iterasi ke-t, Pt
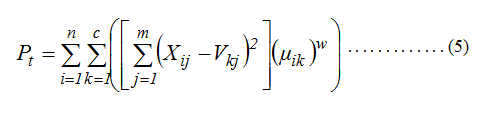
- Perhitungan fungsi objektif Pt dimana nilai variabel fuzzy Xij di kurang dengan dengan pusat cluster Vkjkemudian hasil pengurangannya di kuadradkan lalu masing-masing hasil kuadrad di jumlahkan untuk dikali dengan kuadrad dari derajat keanggotaan μik untuk tiap cluster. Setelah itu jumlahkan semua nilai di semua cluster untuk mendapatkan fungsi objektif Pt.
- Hitung perubahan matriks partisi:
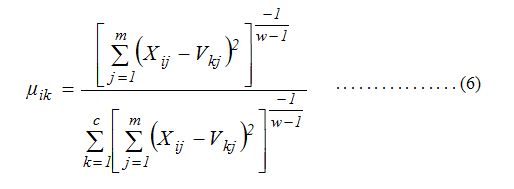 dengan: i=1,2,…n dan k=1,2,..c.
dengan: i=1,2,…n dan k=1,2,..c.
Untuk mencari perubahan matrik partisi μik,pengurangan nilai variabel fuzzy Xij di lakukan kembali terhadap pusat cluster Vkjlalu dikuadradkan. Kemudian dijumlahkan lalu dipangkatkan dengan -1/(w-1) dengan bobot, w=2 hasilnya setiap data dipangkatkan dengan -1. Setelah proses perhitungan dilakukan, normalisasikan semua data derajat keanggotaan baru dengan cara menjumlahkan derajat keanggotaan baru k=1,…c, hasilnya kemudian dibagi dengan derajat keanggotaan yang baru. Proses ini dilakukan agar derajat keanggotaan yang baru mempunyai rentang antara 0 dan tidak lebih dari 1
- Cek kondisi berhenti:a) jika:( |Pt – Pt-1 |< ξ) atau (t>maxIter) maka berhenti.b) jika tidak, t=t+1, ulangi langkah ke-4.
Daftar Pustaka :
[1] Cox, Earl. 2001. The Fuzzy System Handbook. AP Professional
[2] Hari dan Kusumadewi. 2004. Aplikasi Logika Fuzzy untuk Pendukung Keputusan. Yogyakarta: Graha Ilmu.
[3] Kadir, Abdul. 2003. Dasar Pemrograman Web Dinamis Menggunakan PHP. Yogyakarta : ANDI
[4] Kusumadewi, Sri. 2002. Analisis & Desain Sistem Fuzzy Menggunakan Tool Box Matlab. Yogyakarta: Graha Ilmu
[5] Kusumadewi, Sri. 2003. Artificial Intelligence: Teknik dan Aplikasinya. Yogyakarta: Graha Ilmu.
[6] Munir, Rinaldi. 2005. Matematika Diskrit. Bandung: Informatika
[7] Saaty, Thomas L. 2001. Decision Making for Leader, Fourth edition, University of Pittsburgh: RWS publication.
[8] Turban, E., Aronson, J. E., dan Liang, T. P. 2005. Sistem Pendukung Keputusan dan Sistem Cerdas. Terjemahan Dwi Prabantini. Yogyakarta : ANDI
[9] Ravichandran, and Dinakaran, K. 2009. Hybrid Fuzzy C-Means Clustering Technique for Gene Expression Data, Volume 1 Dept. of Computer Science and Engineering Hindustan Institute of Tech., Coimbatore, India: International Journal of Research and Reviews in Applied Sciences, ISSN: 2076-734X, EISSN: 2076-7366


 i=1,2, … , M dan j adalah kolom ke-j
i=1,2, … , M dan j adalah kolom ke-j N adalah Jumlah Fitur dan XT adalah Matrix Transpose dari X
N adalah Jumlah Fitur dan XT adalah Matrix Transpose dari X

 Setiap Baris P adalah eigenvektor Cx
Setiap Baris P adalah eigenvektor Cx









